


The common workflow for git (git flow) uses feature branches, where a separate branch is created for each new feature. Developers implement new functionality on these isolated branches and then merge their changes back into the main or master branch.
The benefits of that workflow are clear: a separate branch can be conveniently deployed and tested in the QA environment, and if critical bugs are detected, it simply won’t get merged into the main branch. Issues can be fixed and code improved in the same branch.
Meanwhile, the main branch remains constantly deployable and protected from that issues.
Unfortunately, this strategy has a significant downside – merge conflicts. With long-living branches, which are at some point inevitable, these conflicts can be too difficult to resolve that it becomes easier to get rid of the branch altogether and start from scratch.
As well, when it’s many conflicts, the merge result may be unpredictable.
However, it’s not the only possible strategy, and this article will cover an alternative way to manage new product features without the disadvantages listed above.
Why Do Merge Conflicts Occur?
According to Git design, merge conflicts happen during merge when branches have different content in the same file line.
To illustrate this, let’s consider a scenario where two teams are implementing updates to the same service. Team A is integrating credit card support, while Team B is revamping the user profile page. It seems that these features have nothing to do with each other.
However, it turns out that the payment-related code was previously located in the same place as the profile page code. So both teams extracted their code into separate branches and rewrote the integration.
Now the question is, who will be the first to merge their changes into the main branch and pretend that the problem is not on their side while the other team tries to resolve the resulting conflict?

The last merge was complicated and had three conflicts.
Trunk-Based Development
Altogether, avoiding merge conflicts is impossible, but we can certainly make them easier to resolve using the following well-known rule:
If an action is difficult and scary, do it more often
In Git terms, this would mean we need to merge as frequently as possible (ideally on every commit). And of course, conflicts will happen more often in that case, but resolving them will be much easier.
It’s called trunk-based development and means pushing changes directly to the main branch and avoiding using branches when unnecessary.
In the example above, if both teams regularly pushed their changes to the main branch, they would quickly notice they were trying to modify the same file.
Even more, they could have avoided issues altogether. The second team would have started making their changes after the first team had already modified the file, considering those updates.
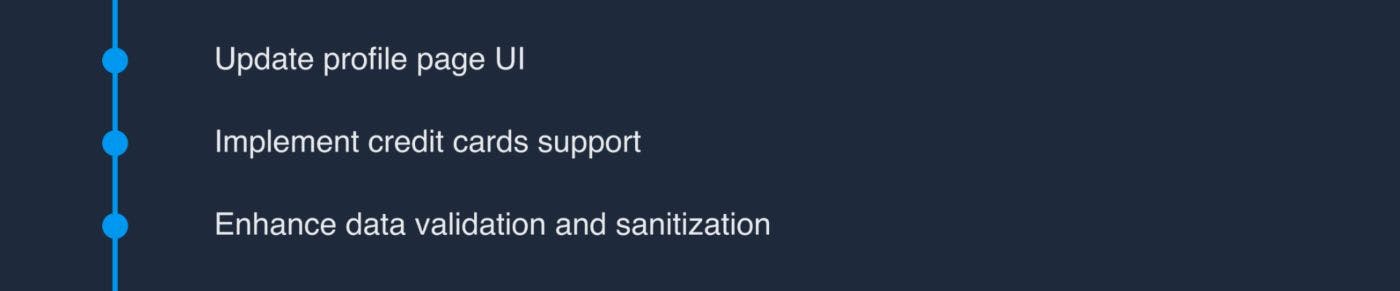
Using trunk-based development solved a conflict for the example above.
An attentive reader might wonder: everything sounds great, but how do we go about testing? Branches per feature allow testing the entire new functionality in isolation before the release; if we continuously integrate changes into the main branch, there will be no chance for that.
Introducing Feature Flags
A feature flag, or a feature toggle, is a simple dynamic flag that allows toggle the particular feature in runtime. Commonly, feature flags also allow enable or disable features for specific groups of users, like QA engineers, staff, specific customers, etc.
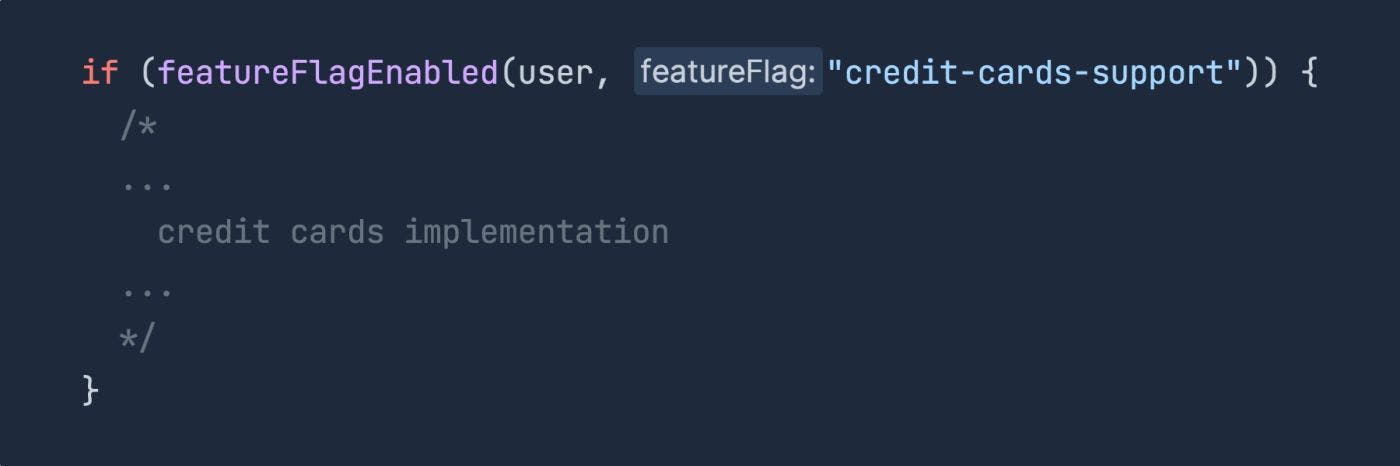
Typical feature flag usage.
The feature flags have several extra advantages:
- Risk-free deploy
- More reliable testing directly in production
- Quickly roll back changes when required.
Using feature flags make pushing changes to the main branch safer. While the feature flag is turned off, the changes don’t affect anyone.
This technique allows working directly with the main branch or creating short-living branches. So, the merge conflicts become pretty rare and resolve quickly.
Conclusion
In summary, trunk-based development combined with feature flags is an excellent technique that helps avoid many problems prompted by conflicting changes in feature branches.
However, as always, there is no one-size-fits-all. It works for a small number of teams that are working in the same repository – increasing this number usually requires some adjustments.
Moreover, it’s always possible to use both methods: use feature branches or feature flags depending on the specific situation and task.
This article was originally published by Vladislav Bakin on Hackernoon.







{kind=link}
{kind=link}
{kind=link}